Note
This technote is not yet published.
Notes on running DRP pipelines using PanDA (Production ANd Distributed Analysis system)
1 Introduction¶
PanDA (Production ANd Distributed Analysis) is a workload management system for distributed (GRID based), Cloud, or HPC computing. PanDA based setups usually include a few leveraged components such as:
- PanDA server [PanDA_documentation], [PanDA_paper]
- JEDI system [JEDI_twiki]
- Harvester [Harvester_documentation], [Harvester_slides], [Harvester_paper]
- Pilot [Pilot_documentation], [Pilot_paper]
- iDDS [iDDS_documentation], [iDDS_slides]
- Monitoring [monitoring_paper]
- CRIC [CRIC_slides]
All these components have a well-defined scope of functionality and its independent installation allows to manage deeply customized instances. For the year 2019, the ATLAS PanDA instance landed 394M computing jobs on 165 computation queues distributed all over the World. There are more than 3000 users who use BigPanDA monitor. PanDA system has been successfully adopted by other experiments, e.g. COMPASS [compass_paper].
In this note, we describe the PanDA setup created for the Rubin evaluation and the data processing test.
2 Setup¶
We have intensively used results of both ATLAS Google POC [atlas_google_poc] and Rubin Google POC [rubin_google_poc] projects. The following components of the setup were configured specifically for this exercise:
- Harvester. A Kubernetes edge service has been configured in the DOMA Harvester instance to handle 7 clusters deployed on the Google Kubernetes Engine. We distinguished all tasks in the workflow by memory requirements into three groups: conventional memory (4GB per pod), high (10.5 GB per pod), and extra_high (117.5 GB per pod). Queues are functioning in the PULL mode for preemptible queues, and in the PUSH mode for non-preemptible queues. This PULL mode continuously provided few instances of pilot idling in the GKE pods and periodically checked for new jobs until reaching the timefloor number of minutes specified in the corresponding PanDA queue. The number of running pilots and, accordingly, number of activated nodes dynamically increased to match the number of jobs immediately ready for submission on a queue. Details of Harvester configuration for using Google Cloud Console described here [harvester_gke_manual].
- Pilot. It is a generic middleware component for grid computing. Instead of submitting payload jobs directly to the grid gatekeepers, pilot factories are used to submit special lightweight jobs referred to here as pilot wrappers that are executed on the worker nodes. The pilot is responsible for pulling the actual payload from the PanDA server and any input files from the Storage Element (SE), executing the payload, uploading the output to the SE, monitoring resource usage, sending the heartbeat signal, evaluation and sending the final job status to the PanDA server. Pilot jobs are started by pilot-starter jobs, which are provided by the Harvester. In the created setup, the pilot uploads the log files from produced by each job to a Google Bucket for long term storage.
- iDDS. This system provides synchronization of payload execution accordingly to the Direct Acyclic Graph (DAG) generated by the BPS subsystem. Its basic role is to check payload processing status and resolve pseudo inputs in tasks successors once the correspondent predecessor job has finished. A PanDA plugin uses the iDDS client to submit a workflow and once submitted, the iDDS sends the payload to the PanDA server and manages its execution. iDDS provides an API for workflow management as a whole such as cancellation, retrial.
- Google Cloud configuration. We defined 7 kubernetes clusters with different type of machines: n2-standard-4 with ~4 cores and ~4 GB of memory per core, n2-custom-4-43008-ext with ~4 cores and ~10.5 GB of RAM per core, n2-custom-2-240640-ext with ~2 cores and ~117.5 GB per core, and n2-custom-6-8960. Part of each CPU power and memory are reserved by GKE for management purpose, this is why each machine can not accept more than 3 jobs. Disk size for all machines was set to 200 GB with ordinary performance type (not SSD). All nodes were preemtible and autoscaling was enabled for both clusters. Data is kept on the Google Storage and accessed using the gc protocol. All payloads are executed in the Docker containers. We have deployed a Docker over Docker configuration (via sharing the host Docker socket) with an outer container being responsible for providing the OSG worker node software stack for landing the Pilot and perform X.509 proxy authentication to communicate with PanDA server. The inner container contains the standard Rubin software published in the official DockerHub repository.
There were additional improvements of JEDI and iDDS core but they were done into the workflow agnostic way.
3 PanDA Queues on GKE Clusters and GCS Buckets¶
3.1 GKE Clusters¶
In the project of panda-dev-1a74, we defined 6 kubernetes (GKE) production clusters and one small GKE test cluster (developmentcluster). All clusters are deployed using correspondent [Terraform] configuration. The repository with deployment scripts are available in the LSST GitHub [deployemnt_project].
Currently there are 7 GKE clusters:
% gcloud container clusters list
NAME LOCATION MASTER_VERSION MASTER_IP MACHINE_TYPE NODE_VERSION NUM_NODES STATUS
developmentcluster us-central1 1.22.8-gke.2200 35.239.22.197 n2-custom-6-8960 1.21.10-gke.1500 * 1 RUNNING
extra-highmem us-central1 1.22.8-gke.2200 35.193.135.73 n2-custom-2-240640-ext 1.21.10-gke.1500 * 4 RUNNING
extra-highmem-non-preempt us-central1 1.22.8-gke.2200 104.198.73.122 n2-custom-2-240640-ext 1.22.8-gke.200 * 2 RUNNING
highmem us-central1 1.21.11-gke.1100 35.224.254.34 n2-custom-4-43008-ext 1.21.11-gke.900 * 3 RUNNING
highmem-non-preempt us-central1 1.21.11-gke.1100 35.193.45.57 n2-custom-4-43008-ext 1.21.11-gke.1100 5 RUNNING
merge us-central1 1.22.8-gke.2200 34.70.152.234 n2-standard-4 1.21.10-gke.1500 * 2 RUNNING
moderatemem us-central1 1.21.11-gke.1100 34.69.213.236 n2-standard-4 1.21.5-gke.1302 * 3 RUNNING
You can find the details about the associated machine type below.
The info for the machine-type n2-standard-4:
% gcloud compute machine-types describe n2-standard-4
Did you mean zone [us-central1-c] for machine type: [n2-standard-4]
(Y/n)? Y
creationTimestamp: '1969-12-31T16:00:00.000-08:00'
description: 4 vCPUs 16 GB RAM
guestCpus: 4
id: '901004'
imageSpaceGb: 0
isSharedCpu: false
kind: compute#machineType
maximumPersistentDisks: 128
maximumPersistentDisksSizeGb: '263168'
memoryMb: 16384
name: n2-standard-4
selfLink: https://www.googleapis.com/compute/v1/projects/panda-dev-1a74/zones/us-central1-c/machineTypes/n2-standard-4
zone: us-central1-c
The info for the machine-type n2-custom-4-43008-ext:
% gcloud compute machine-types describe n2-custom-4-43008-ext
Did you mean zone [us-central1-c] for machine type:
[n2-custom-4-43008-ext] (Y/n)? y
description: Custom created machine type.
guestCpus: 4
id: '1735166830592'
isSharedCpu: false
kind: compute#machineType
maximumPersistentDisks: 128
maximumPersistentDisksSizeGb: '263168'
memoryMb: 43008
name: n2-custom-4-43008-ext
selfLink: https://www.googleapis.com/compute/v1/projects/panda-dev-1a74/zones/us-central1-c/machineTypes/n2-custom-4-43008-ext
zone: us-central1-c
The info for the machine-type n2-custom-2-240640-ext:
% gcloud compute machine-types describe n2-custom-2-240640-ext
Did you mean zone [us-central1-c] for machine type:
[n2-custom-2-240640-ext] (Y/n)? Y
description: Custom created machine type.
guestCpus: 2
id: '867583634432'
isSharedCpu: false
kind: compute#machineType
maximumPersistentDisks: 128
maximumPersistentDisksSizeGb: '263168'
memoryMb: 240640
name: n2-custom-2-240640-ext
selfLink: https://www.googleapis.com/compute/v1/projects/panda-dev-1a74/zones/us-central1-c/machineTypes/n2-custom-2-240640-ext
zone: us-central1-c
3.2 Pilot scripts and env¶
Pilot jobs are started by a pilot shell wrapper. While for GKE clusters, there is another python script, pilot starter, to run the pilot wrapper.
In addition, the pilot starter includes some other functions:
- Write out the harvester log (including the log from the pilot starter, the pilot wrapper and the pilot job)
- Create a real-time logger, analyze/filter the harvester log, and send to the Google Cloud Logging, in the log name: Panda-WorkerLog.
All the scripts and the Dockerfile to build the pilot Docker container are available in the github repo lsst-dm/panda-conf.
And the latest script files, and the used pilot package, are stored in one Rubin GCS bucket drp-us-central1-containers
The built pilot Docker container is stored in Google Artifact Registry (GAR) under us-central1-docker.pkg.dev/panda-dev-1a74/pilot/centos.
3.2.1 File uploading to GCS¶
Files can uploaded into the Google Cloud Storage bucket drp-us-central1-containers through:
- Google cloud console
- or gsutil command, gsutils cp, for example:
gsutil cp pilot3_starter-20220913.py gs://drp-us-central1-containers/
In addition, the uploaded file access should be made public. The file access can also be changed through Google Cloud Console, or gsutil command:
gsutil acl ch -u AllUsers:R gs://drp-us-central1-containers/pilot3_starter-20220913.py
More detailed usage can be found at the page Discover object storage with the gsutil tool.
3.3 PanDA Queues¶
The PanDA queues are configured in the [CRIC] system to match particular job requirements. For the actual list of PanDA queues, please refer to the PanDA user guide.
3.3.1 Management of the PanDA queues¶
The queues are configured and managed on the harvester server, ai-idds-02.cern.ch. While the harvester service is managed by the uWSGI tool. The havester source code can be found at https://github.com/HSF/harvester.
There are 3 main commands in the shell script /opt/harvester/etc/rc.d/init.d/panda_harvester-uwsgi:
- start: to start the harvester service.
- stop: to stop the running harvester service.
- reload: to reload the harvester configuration.
3.3.2 Configuration of the PanDA queues¶
The queues configuration files are available in the GitHub repository the panda-conf github repo.
The PanDA queue configuration related with the pilot behavior is defined in the CRIC system, which is downloaded by the pilot wrapper, then is used in pilot jobs. A copy of json file for each queue is saved in the github repo lsst-dm/panda-conf.
Please note that the parameter maxrss in the cric json file specifies the maximum requested memory to start a POD on the corresponding GKE cluster. This number should not exceed the value of parameter memoryMb shown on the GKE cluster machine type output, minus some overhead from the kubernetes components on the GKE cluster, otherwise no POD could be started.
The harvester json file panda_queueconfig.json defines all PanDA queues on the harvester server. The kube_job.yaml provides Kubernetes job configuration for DOMA_LSST_GOOGLE_TEST_HIMEM, DOMA_LSST_GOOGLE_TEST_EXTRA_HIMEM, DOMA_LSST_GOOGLE_MERGE queues. The kube_job_moderate.json defines K8s jobs on DOMA_LSST_GOOGLE_TEST and kube_job_non_preempt.yaml for DOMA_LSST_GOOGLE_TEST_HIMEM_NON_PREEMPT and DOMA_LSST_GOOGLE_TEST_EXTRA_HIMEM_NON_PREEMPT. The yaml file job_dev-prmon.yaml is for the test queue DOMA_LSST_DEV.
The above “k8s_yaml_file” files instruct POD:
- what container image is used.
- what credentials are passed.
- what commands run in the container on the pod.
While the “k8s_config_file” files associate PanDA queues with their corresponding GKE clusters, which will be explained in the next subsection.
Currently the container image is us-central1-docker.pkg.dev/panda-dev-1a74/pilot/centos:CentOS7-gar_auth, with the env to run pilot jobs. The Dockerfile to build this pilot container could be found at: https://github.com/lsst-dm/panda-conf/blob/main/pilot-scripts-for-GKE/pilotContainer/Dockerfile.
For the production queues, the commands inside the container are passed to “bash -c”:
whoami;cd /tmp;export ALRB_noGridMW=NO; wget https://storage.googleapis.com/drp-us-central1-containers/pilots_starter_d3.py; chmod 755 ./pilots_starter_d3.py; ./pilots_starter_d3.py || true
It will download the pilot package and start a new pilot job.
Please note that the inner Rubin SW Docker container and the outer pilot Docker container share with the host the Docker socket and Daemon, so the bind mount path between the inner and outer containers must be the same on the host machine. For example, in order to bind-mount logDir=/tmp/panda/${PANDAID} (as shown in the parameter runnerCommand of the bps yaml file), the volume /tmp/panda has already been created on the host machine and bind-mounted onto the outer Docker container, as specified in the queue configuration yaml files:
volumes:
- name: temp-volume
hostPath:
path: /tmp/panda
type: DirectoryOrCreate
For debugging purposes, a POD node can be created independently with a test yaml file. But a different metadata name should be used i.e. test-job, in the yaml file. For example:
kubectl create -f test.yaml
kubectl get pods -l job-name=test-job
kubectl exec -it $podName -- /bin/bash
which creates a pod in the job-name of test-job, and enters to the container on that POD to debug, where $podName is the POD name found on the command “kubectl get pods”.
3.3.3 Association of PanDA queues with GKE Clusters¶
In order to associate a new GKE cluster with the corresponding PanDA queue, a “k8s_config_file” file need to be created. Take an example of the cluster “extra-highmem-non-preempt”:
export KUBECONFIG=/data/idds/gcloud_config_rubin/kube_extra_large_mem_non_preempt
gcloud container clusters get-credentials --region=us-central1 extra-highmem-non-preempt
chmod og+rw $KUBECONFIG
3.3.4 GKE Authentication for PanDA Queues¶
The environment variable CLOUDSDK_CONFIG defines the location of Google Cloud SDK’s config files. On the harvester server machine the environment variable is defined to /data/idds/gcloud_config in the file /opt/harvester/etc/rc.d/init.d/panda_harvester-uwsgi. During new wokers creation the harvester server needs to run the Google cloud authentication command:
gcloud config config-helper --format=json
Please be aware that all the files and directories under $CLOUDSDK_CONFIG should be owned by the account running the harvester service:
[root@ai-idds-02 etc]# ls -ltA /data/idds/gcloud_config
total 68
-rw-------. 1 iddssv1 zp 9216 Jul 27 20:55 access_tokens.db
-rw-------. 1 iddssv1 zp 5 Jul 27 20:55 gce
drwxr-xr-x. 30 iddssv1 zp 4096 Jul 27 02:33 logs
-rw-------. 1 iddssv1 zp 5883 Jul 14 09:54 .kube
-rw-r--r--. 1 iddssv1 zp 36 Jul 14 09:51 .last_survey_prompt.yaml
-rw-r--r--. 1 iddssv1 zp 0 Jun 14 21:06 config_sentinel
drwx------. 6 iddssv1 zp 4096 Jun 14 21:06 legacy_credentials
-rw-------. 1 iddssv1 zp 14336 Jun 14 21:06 credentials.db
drwxr-xr-x. 2 iddssv1 zp 4096 May 26 19:59 configurations
-rw-------. 1 iddssv1 zp 4975 Apr 19 2021 .kube_conv
-rw-r--r--. 1 iddssv1 zp 7 Aug 26 2020 active_config
By default, gcloud commands write log files into $CLOUDSDK_CONFIG/logs, and will automatically clear log files and directories more than 30 days old, uncless the flag disable_file_logging is enabled.
To check which account is used in the Google cloud authentication, just run gcloud auth list:
% gcloud auth list
Credentialed Accounts
ACTIVE ACCOUNT
* dev-panda-harvester@panda-dev-1a74.iam.gserviceaccount.com
gcs-access@panda-dev-1a74.iam.gserviceaccount.com
spadolski@lsst.cloud
yesw@lsst.cloud
To set the active account, run:
$ gcloud config set account `ACCOUNT`
To add a new account into the auth list, just run:
% gcloud auth login
For details, please read https://cloud.google.com/sdk/gcloud/reference/auth/login.
The GKE authentication account has been changed to use the service account dev-panda-harvester.
To modify the active account, first run the Google cloud authentication “gcloud auth login”, then run gcloud config set account `ACCOUNT`.
3.3.5 AWS Access Key for S3 Access to GCS Buckets¶
Rubin jobs need to access the GCS butler bucket in s3 botocore, hence AWS authentication is required. The AWS access secret key is stored in the environment variables AWS_ACCESS_KEY_ID and AWS_SECRET_ACCESS_KEY.
Currently the AWS access key from the service account butler-gcs-butler-gcs-data-sa@data-curation-prod-fbdb.iam.gserviceaccount.com is used as shown on the interoperability setting page for the project data-curation-prod-fbdb.
The AWS access key is passed to the POD nodes via kubernetes secrets in the data field which have to be base64-encoded strings. Then the AWS access key is passed as environment variables into the Rubin docker containers.
3.4 GCS Buckets¶
In the Google Cloud Storage (GCS), we defined two buckets, drp-us-central1-containers and drp-us-central1-logging, as shown below:

The 3rd bucket in the name of “us.artifacts.*”, was automatically created in the Google Cloud Build, to store the build container images.
As the bucket name indicates, the bucket drp-us-central1-containers accommodate container image files, the pilot-related files and panda queue configuration files. The other bucket drp-us-central1-logging stores the log files of pilot and payload jobs.
The logging bucket is configured in Uniform access mode, allowing public access, and allowing a special service account gcs-access with the permission of roles/storage.legacyBucketWriter and roles/storage.legacyObjectReader. The credential json file of this special service account is generated in the following command:
gcloud iam service-accounts keys create gcs-access.json --iam-account=gcs-access@${projectID}.iam.gserviceaccount.com
Where $projectID is panda-dev-1a74. Then it is passed to the container on the POD nodes via the secret name gcs-access, with the environmental variable GOOGLE_APPLICATION_CREDENTIAL pointing to the json file.
3.5 Real-time Logging for Pilot Jobs¶
Pilot logs associated with payload jobs are written onto the GCS bucket drp-us-central1-logging. We also provide (near)real-time logging for pilot logs on Google Cloud Logging, regardless whether the pilot job is idling or running some payload jobs. It could help provide real-time logging of whole pilot jobs as well as the parental pilot wrapper jobs. In addition, it is very useful in case pilot logs could not be written onto the GCS for some reasons such as pilot jobs being killed or problems with GCS.
The real-time logging for pilot jobs is implemented in the pilot starter python script pilot3_starter.py, with the class RealTimeLogger. The pilot wrapper log (which already includes the pilot log itself) file /tmp/wrapper-wid.log, is parsed and filtered, then written into the log name Panda-WorkerLog, different from the log name for payload job logs.
Usually only logs containg a valid time stamp at the beginning is kept and written onto Google Cloud Logging. For each log, the hostname is added. And PanDA job ID and job name are also added if available.
Normally the log severity level is just copied from the pilot log level. However, if the payload stderr dump message indicates that the payload failed, the log severity level would be set to ERROR for that message and also pilot logs containing “| payload stderr dump”, “| add_error_codes”, or “| perform_initial_payload_error_analysis”.
For the logs of payload stderr dump, the last 10 non-blank lines (though not containing a time stamp) following the line of “| payload stderr dump” are also appended into that log.
4 Job Run Procedure in PanDA¶
The PanDA system can be seen in the following graph:
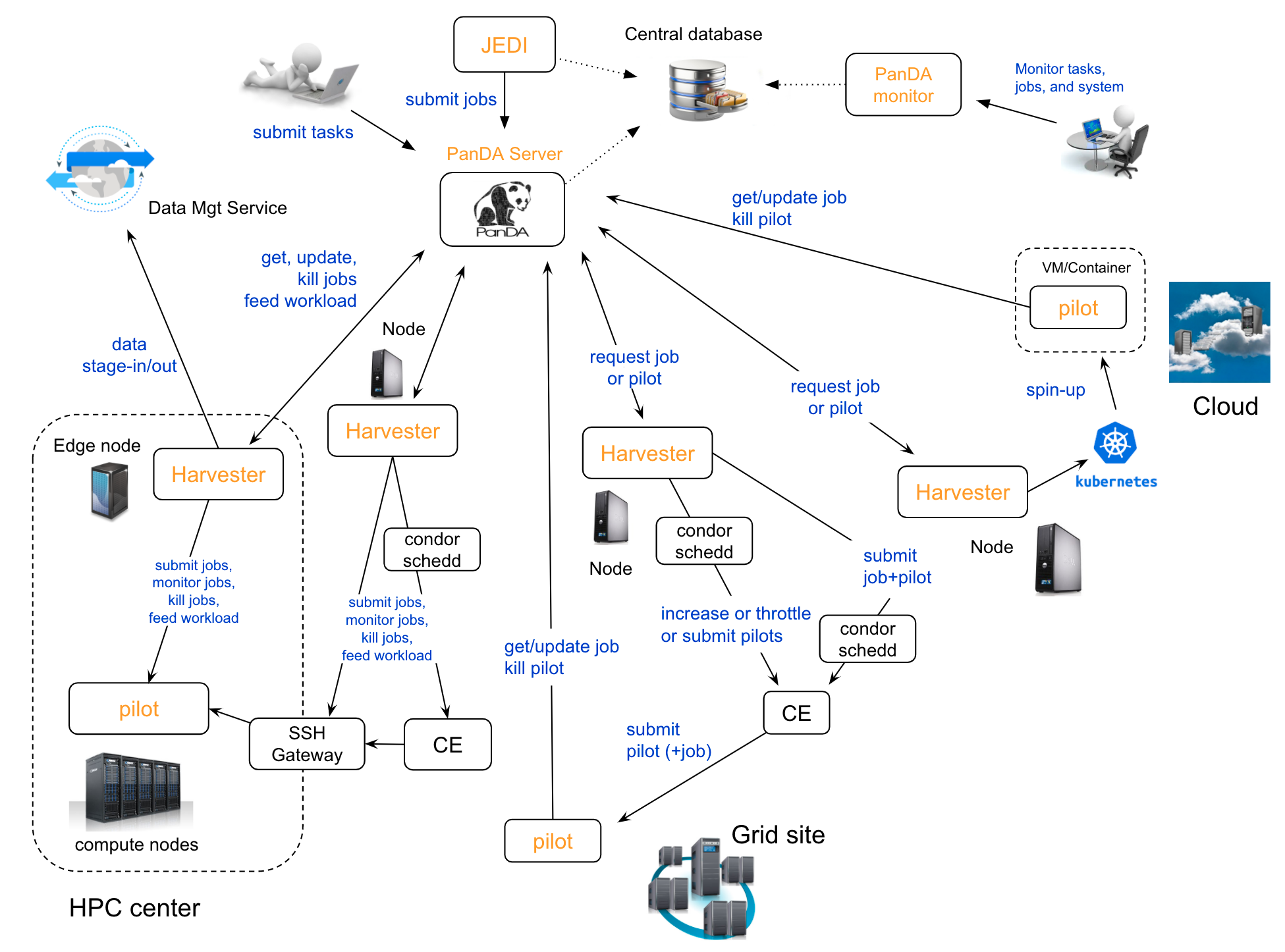
The detailed description of these components is presented in the slides of PanDA status update talk.
4.1 Job Submission¶
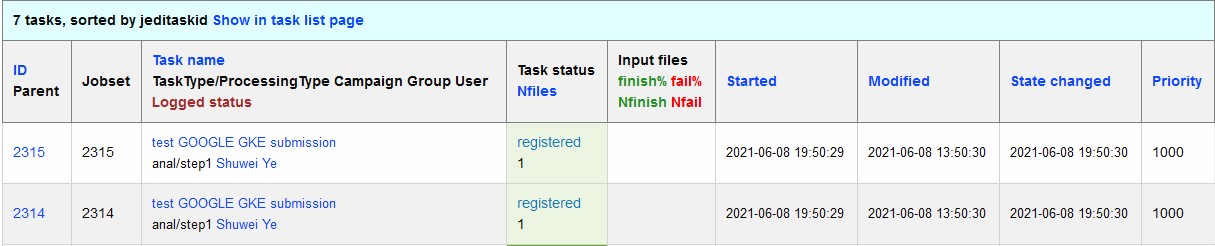
As described in the PanDA Orchestration User Guide, jobs generated by the BPS subsystem end then grouped in into tasks by PanDA plugin using jobs labels as a grouping criteria. In this way, each task performs the unique principal operations over different Data/Node ids. Each job has its own input Data/Node id. The submission YAML file is described here: configuration YAML file. Once PanDA plugin generates a workflow of dependent jobs united into tasks it submits them into iDDS performing transitional authentication in PanDA server. The PanDA monitoring page will show the tasks in the status of registered, as shown below:
4.2 Job Starting¶
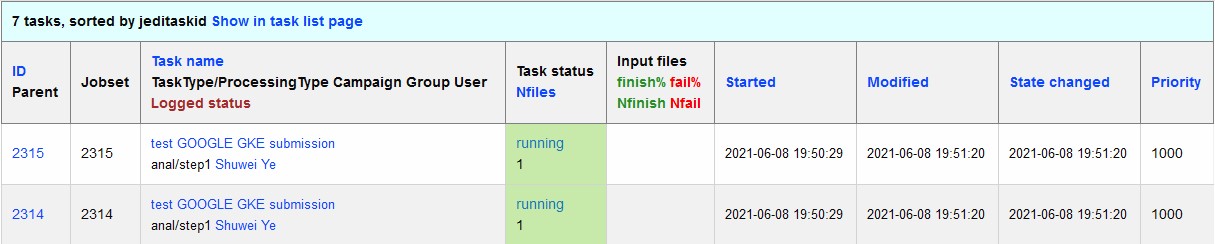
The harvester server, ai-idds-02.cern.ch, is continuously querying the PanDA server about the number of jobs to run, then triggers the corresponding GKE cluster to start up the needed POD nodes. this moment, those tasks/jobs status will be changed into running, as shown below:
4.3 Job Running¶
The POD nodes run in the pilot/Rubin container, for example, us.gcr.io/panda-dev-1a74/centos:7-stack-lsst_distrib-w_2021_21_osg_d3, as configured in the GKE cluster. Each jobs on the POD nodes start one pilot job inside the container. The pilot job will first get the corresponding PanDA queue configuration and the associated storage ddmendpoint (RSE) configuration from CRIC.
The pilot job uses the provided job definition in case of PUSH mode, or will get retrieve definition in case of PULL mode. Then the pilot job runs the provided payload job. In case of PULL mode, one pilot job could get and run multiple payload jobs one by one. After the payload job finishes, the pilot will use the python client for GCS to write the payload job log file into the Google Cloud Storage bucket, which is defined in the PanDA queue and RSE configuration. Then the pilot will update the job status including the public access URL to the log files, as shown below:
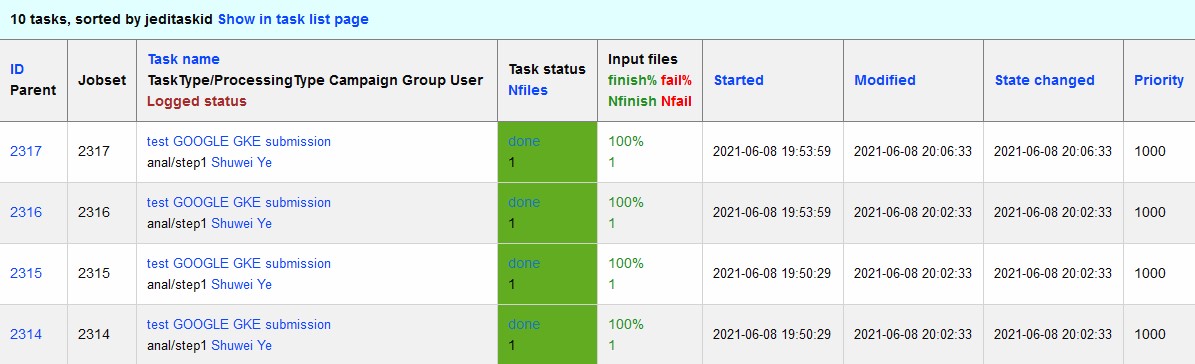
If the jobs have not finished successfully, the job status would be failed.
The pilot communication with the PanDA server is authenticated with a valid grid proxy, which is passed to the container through POD. Similarly, a credential json file of the GCS bucket access service account is passed to the container, in order to write/access to the GCS bucket in the python client for the Google Cloud Storage.
4.4 Job Monitoring¶
Users can visit the PanDA monitoring server, https://panda-doma.cern.ch/, to check the workflow/task/job status. The PanDA monitor fetches the payload information from the central database. The monitoring provides the drill down functionality starting from a workflow and finishing by a particular job log. Clicking on the task IDs will go into the details of each task, then clicking on the number under the job status such as running, finished, or failed, will show the list of jobs in that status. You can check each job details by following the PanDA ID number.
4.5 Real-time Logging for Payload Jobs¶
The Rubin jobs on the PanDA queues are also provided with (near)real-time logging on Google Cloud Logging in log name Panda-RubinLog. Once the jobs have been running on the PandDA queues, users can check the json format job logs on the Google Logs Explorer.
The enviromental variable REALTIME_LOGFILES defines the json filename to be produced by Rubin payload jobs. A pilot job continuously reads this json file every 5 seconds, and sends the found lines together with associated PanDA job ID and task ID.
The envvar REALTIME_LOGFILES=payload-log.json is set in the Kubernetes job yaml file for each queue, under the container env section, as well as 3 other real-time envvars:
- USE_REALTIME_LOGGING=”yes”
- REALTIME_LOGGING_SERVER=”google-cloud-logging”
- REALTIME_LOGNAME=”Panda-RubinLog”
which correspond to the following 3 options in the main pilot python script pilot.py:
--use-realtime-logging--realtime-logging-server--realtime-logname
5 Support¶
There are two lines of support: Rubin-specific and core PanDA components. For front line support we established a dedicated slack channel: #rubinobs-panda-support. If an occurred problem goes beyond the Rubin deployment, a correspondent development team could be involved. Support channel for each subsystem of the setup provided in particular documentation.
6 References¶
| [PanDA_documentation] | PanDA Documentation Page https://panda-wms.readthedocs.io/en/latest/ |
| [PanDA_paper] | Evolution of the ATLAS PanDA workload management system for exascale computational science https://www.researchgate.net/publication/274619051_Evolution_of_the_ATLAS_PanDA_workload_management_system_for_exascale_computational_science |
| [JEDI_twiki] | JEDI Twiki Page https://twiki.cern.ch/twiki/bin/view/PanDA/PandaJEDI |
| [Harvester_documentation] | Harvester Documentation https://github.com/HSF/harvester/wiki |
| [Harvester_slides] | Harvester Slides http://cds.cern.ch/record/2625435/files/ATL-SOFT-SLIDE-2018-400.pdf |
| [Harvester_paper] | Harvester: an edge service harvesting heterogeneous resources for ATLAS https://www.epj-conferences.org/articles/epjconf/pdf/2019/19/epjconf_chep2018_03030.pdf |
| [Pilot_documentation] | Pilot documentation https://github.com/PanDAWMS/pilot2/wiki |
| [Pilot_paper] | The next generation PanDA Pilot for and beyond the ATLAS experiment https://cds.cern.ch/record/2648507/files/Fulltext.pdf |
| [iDDS_documentation] | iDDS documentation https://idds.readthedocs.io/en/latest/ |
| [iDDS_slides] | iDDS slides https://indico.cern.ch/event/849155/contributions/3576915/attachments/1917085/3170006/idds_20100927_atlas_sc_week.pdf |
| [monitoring_paper] | BigPanDA monitoring paper https://inspirehep.net/files/37c79d51eadd0e8ec8e019aef8bbcfd8 |
| [CRIC_slides] | https://indico.cern.ch/event/578991/contributions/2738744/attachments/1538768/2412065/20171011_GDB_CRIC_sameNEC.pdf |
| [compass_paper] | http://ceur-ws.org/Vol-1787/385-388-paper-67.pdf |
| [atlas_google_poc] | https://indico.bnl.gov/event/8608/contributions/38034/attachments/28380/43694/HEP_Google_May26_2020.pdf |
| [rubin_google_poc] | https://dmtn-157.lsst.io/ |
| [harvester_gke_manual] | https://github.com/HSF/harvester/wiki/Google-Kubernetes-Engine-setup-and-useful-commands |
| [Terraform] | https://learn.hashicorp.com/collections/terraform/gcp-get-started |
| [deployemnt_project] | https://github.com/lsst/idf_deploy |
| [CRIC] | https://datalake-cric.cern.ch/ |